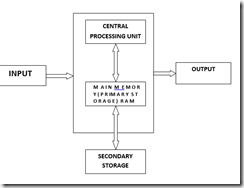
STORAGE DEVICES
The purpose of storage in a computer is to hold data or information and get that data to the CPU as quickly as possible when it is needed. Computers use disks for storage: hard disks that are located inside the computer, and floppy or compact disks that are used externally.
• Computers Method of storing data & information for long term basis i.e. even after PC is switched off.
• It is non - volatile
• Can be easily removed and moved & attached to some other device
• Memory capacity can be extended to a greater extent
• Cheaper than primary memory
Storage Involves Two Processes
a) Writing data b) Reading data
Floppy DisksThe floppy disk drive (FDD) was invented at IBM by Alan Shugart in 1967. The first floppy drives used an 8-inch disk (later called a "diskette" as it got smaller), which evolved into the 5.25- inch disk that was used on the first IBM Personal Computer in August 1981. The 5.25 -inch disk held 360 kilobytes compared to the 1.44 megabyte capacity of today's 3.5-inch diskette.
The 5.25-inch disks were dubbed "floppy" because the diskette packaging was a very flexible plastic envelope, unlike the rigid case used to hold today's 3.5-inch diskettes.
By the mid-1980s, the improved designs of the read/write heads, along with improvements in the magnetic recording media, led to the less-flexible, 3.5-inch, 1.44- megabyte (MB) capacity FDD in use today. For a few years, computers had both FDD sizes (3.5- inch and 5.25-inch). But by the mid-1990s, the 5.25-inch version had fallen out of popularity, partly because the diskette's recording surface could easily become contaminated by fingerprints through the open access area.
When you look at a floppy disk, you'll see a plastic case that measures 3 1/2 by 5 inches. Inside that case is a very thin piece of plastic that is coated with microscopic iron particles. This disk is much like the tape inside a video or audio cassette. Basically, a floppy disk drive reads and writes data to a small, circular piece of metal-coated plastic similar to audio cassette tape.
At one end of it is a small metal cover with a rectangular hole in it. That cover can be moved aside to show the flexible disk inside. But never touch the inner disk - you could damage the data that is stored on it. On one side of the floppy disk is a place for a label. On the other side is a silver circle with two holes in it. When the disk is inserted into the disk drive, the drive hooks into those holes to spin the circle. This causes the disk inside to spin at about 300 rpm! At the same time, the silver metal cover on the end is pushed aside so that the head in the disk drive can read and write to the disk.
Floppy disks are the smallest type of storage, holding only 1.44MB.
3.5-inch Diskettes (Floppy Disks) features:
• Spin rate: app. 300 revolutions per minute (rpm)
• High density (HD) disks more common today than older, double density (DD) disks
• Storage Capacity of HD disks is 1.44 MB
Floppy Disk Drive Terminology
Floppy disk - Also called diskette. The common size is 3.5 inches.
Floppy disk drive - The electromechanical device that reads and writes floppy disks. Track - Concentric ring of data on a side of a disk.
Sector - A subset of a track, similar to wedge or a slice of pie.
It consists of a read/write head and a motor rotating the disk at a high speed of about 300 rotations per minute. It can be fitted inside the cabinet of the computer and from outside, the slit where the disk is to be inserted, is visible. When the disk drive is closed after inserting the floppy inside, the monitor catches the disk through the Central of Disk hub, and then it starts rotating.
There are two read/write heads depending upon the floppy being one sided or two sided. The head consists of a read/write coil wound on a ring of magnetic material. During write operation, when the current passes in one direction, through the coil, the disk surface touching the head is magnetized in one direction. For reading the data, the procedure is reverse. I.e. the magnetized spots on the disk touching the read/write head induce the electronic pulses, which are sent to CPU.
The major parts of a FDD include:Read/Write Heads: Located on both sides of a diskette, they move together on the same assembly. The heads are not directly opposite each other in an effort to prevent interaction between write operations on each of the two media surfaces. The same head is used for reading and writing, while a second, wider head is used for erasing a track just prior to it being written. This allows the data to be written on a wider "clean slate," without interfering with the analog data on an adjacent track.
Drive Motor: A very small spindle motor engages the metal hub at the center of the diskette, spinning it at either 300 or 360 rotations per minute (RPM).
Stepper Motor : This motor makes a precise number of stepped revolutions to move the read/write head assembly to the proper track position. The read/write head assembly is fastened to the stepper motor shaft.
Mechanical Frame : A system of levers that opens the little protective window on the diskette to allow the read/write heads to touch the dual-sided diskette media. An external button allows the diskette to be ejected, at which point the spring-loaded protective window on the diskette closes.
Circuit Board : Contains all of the electronics to handle the data read from or written to the diskette. It also controls the stepper-motor control circuits used to move the read/write heads to each track, as well as the movement of the read/write heads toward the diskette surface.
Electronic optics check for the presence of an opening in the lower corner of a 3.5-inch diskette (or a notch in the side of a 5.25-inch diskette) to see if the user wants to prevent data from being written on it.
Hard DisksYour computer uses two types of memory: primary memory which is stored on chips located
on the motherboard, and secondary memory that is stored in the hard drive. Primary memory holds all of the essential memory that tells your computer how to be a computer. Secondary memory holds the information that you store in the computer.
Inside the hard disk drive case you will find circular disks that are made from polished steel. On the disks, there are many tracks or cylinders. Within the hard drive, an electronic reading/writing device called the head passes back and forth over the cylinders, reading information from the disk or writing information to it. Hard drives spin at 3600 or more rpm (Revolutions Per Minute) - that means that in one minute, the hard drive spins around over 7200 times!
Optical Storage• Compact Disk Read-Only Memory (CD-ROM)
• CD-Recordable (CD-R)/CD-Rewritable (CD-RW)
• Digital Video Disk Read-Only Memory (DVD-ROM)
• DVD Recordable (DVD-R/DVD Rewritable (DVD-RW)
• Photo CD
Optical Storage Devices Data is stored on a reflective surface so it can be read by a beam of laser light. Two Kinds of Optical Storage Devices
• CD-ROM (compact disk read-only memory)
• DVD-ROM (digital video disk read-only memory)
Compact DisksInstead of electromagnetism, CDs use pits (microscopic indentations) and lands (flat surfaces) to store information much the same way floppies and hard disks use magnetic and non-magnetic storage. Inside the CD-Rom is a laser that reflects light off of the surface of the disk to an electric eye. The pattern of reflected light (pit) and no reflected light (land) creates a code that represents data.
CDs usually store about 650MB. This is quite a bit more than the 1.44MB that a floppy disk stores. A DVD or Digital Video Disk holds even more information than a CD, because the DVD can store information on two levels, in smaller pits or sometimes on both sides.
Recordable Optical Technologies• CD-Recordable (CD-R)
• CD-Rewritable (CD-RW)
• PhotoCD
• DVD-Recordable (DVD-R)
• DVD-RAM
CD ROM - Compact Disc Read Only Memory.Unlike magnetic storage device which store data on multiple concentric tracks, all CD formats store data on one physical track, which spirals continuously from the center to the outer edge of the recording area. Data resides on the thin aluminum substrate immediately beneath the label. The data on the CD is recorded as a series of microscopic pits and lands physically embossed on an aluminum substrate. Optical drives use a low power laser to read data from those discs without physical contact between the head and the disc which contributes to the high reliability and permanence of storage device.
To write the data on a CD a higher power laser are used to record the data on a CD. It creates the pits and land on aluminum substrate. The data is stored permanently on the disc. These types of discs are called as WORM (Write Once Read Many). Data written to CD cannot subsequently be deleted or overwritten which can be classified as advantage or disadvantage depending upon the requirement of the user. However if the CD is partially filled then the more data can be added to it later on till it is full. CDs are usually cheap and cost effective in terms of storage capacity and transferring the data.
The CD‘s were further developed where the data could be deleted and re written. These types of CDs are called as CD Rewritable. These types of discs can be used by deleting the data and making the space for new data. These CD‘s can be written and rewritten at least 1000 times.
CD ROM DriveCD ROM drives are so well standardized and have become so ubiquitous that many treat them as commodity items. Although CD ROM drives differ in reliability, which standards they support and numerous other respects, there are two important performance measures.
· Data transfer rate
· Average access
Data transfer rate: Data transfer rate means how fast the drive delivers sequential data to the interface. This rate is determined by drive rotation speed, and is rated by a number followed by
‗X‘. All the other things equal, a 32X drive delivers data twice the speed of a 16X drive. F ast data transfer rate is most important when the drive is used to transfer the large file or many sequential smaller files. For example: Gaming video.
CD ROM drive transfers the data at some integer multiple of this basic 150 KB/s 1X rate. Rather than designating drives by actual KB/s output drive manufacturers use a multiple of the standard
1X rate. For example: a 12X drive transfer data at (12*150KB/s) 1800 KB/s and so on.
The data on a CD is saved on tracks, which spirals from the center of the CD to outer edge. The portions of the tracks towards center are shorter than those towards the edge. Moving the data
under the head at a constant rate requires spinning the disc faster as the head moves from the center where there is less data per revolution to the edge where there is more data. Hence the rotation rate of the disc changes as it progresses from inner to outer portions of the disc.
CD WritersCD recordable and CD rewritable drives are collectively called as CD writers or CD burners.
They are essentially CD ROM drives with one difference. They have a more powerful laser that, in addition to reading discs, can record data to special CD media.
Pen Drives / Flash Drives
· Pen Drives / Flash Drives are flash memory storage devices.
· They are faster, portable and have a capability of storing large data.
· It consists of a small printed circuit board with a LED encased in a robust plastic
· The male type connector is used to connect to the host PC
· They are also used a MP3 players
NUMBER SYSTEMS
| Binary | Decimal | Octal | Hexadecimal |
| 0000 | 00 | 0 | 0 |
| 0001 | 01 | 1 | 1 |
| 0010 | 02 | 2 | 2 |
| 0011 | 03 | 3 | 3 |
| 0100 | 04 | 4 | 4 |
| 0101 | 05 | 5 | 5 |
| 0110 | 06 | 6 | 6 |
| 0111 | 07 | 7 | 7 |
| 1000 | 08 | 10 | 8 |
| 1001 | 09 | 11 | 9 |
| 1010 | 10 | 12 | A |
| 1011 | 11 | 13 | B |
| 1100 | 12 | 14 | C |
| 1101 | 13 | 15 | D |
| 1110 | 14 | 16 | E |
| 1111 | 15 | 17 | F |